Welcome to the first instalment of AI Project Pulse’s core series, Managing Innovative AI Projects. Before you draft a single requirement or allocate a single resource, there is one fundamental question your team must answer: What kind of AI project are we actually doing?
The most common cause of AI project failure isn’t a lack of talent or technology; it’s a mismatch between the project’s inherent nature and the management approach applied to it. Using the rigorous, risk-averse process of a pharmaceutical rollout to manage a rapid prototype is a recipe for stagnation. Applying a lightweight agile sprint to a project with profound ethical and legal implications is a blueprint for disaster.
The first discipline of successful AI delivery is to know your starting point. To simplify this, we can map the horizon of AI initiatives into a clear Project Typology. This classification, based on what you intend to build, its output, and its primary user, is your indispensable compass. It provides the foundational logic for every decision that follows how rigorously you govern the lifecycle, where you focus risk mitigation, and what performance metrics truly matter.
Here are the five fundamental types of AI projects as we have defined in my book “Managing Innovative AI Projects co-authored with Prof. Alain Abran.
1. Incremental Innovation: The Optimizer
Core Aim: Enhance existing AI-powered applications through tuning, optimization, or feature expansion.
Primary User: Business or customer end-users.
Key Output: An upgraded, more effective version of a current system.
Example: Improving a recommendation engine’s accuracy by adding real-time behavioral context; releasing a faster, more precise fraud detection model in your SaaS platform.
Your Management Mantra:“Efficiency and Reliability.” The lifecycle is well-defined, risks are primarily technical (performance regression, data drift), and success is measured by clear KPIs against a known baseline.
2. Disruptive Innovation: The Game-Changer
Core Aim: Introduce a novel AI application that creates new markets or fundamentally redefines existing ones.
Primary User: External customers or entire industries.
Key Output: A transformative new product or service.
Example: Deploying autonomous delivery vehicles; launching an AI-powered diagnostic tool that outperforms traditional methods.
Your Management Mantra:“Vision and Adoption.” The lifecycle is highly adaptive, risks are market-facing (user acceptance, regulatory response, scalability), and success metrics must balance technical viability with ecosystem adoption and business model validation.
3. Applied Research: The Pioneer
Core Aim: Explore novel algorithms, architectures, or capabilities where the path to a working solution is unknown.
Primary User: Internal research and development teams; outputs later feed product teams.
Key Output: A research prototype, paper, or proof-of-concept.
Example: Developing a new, more efficient transformer architecture for edge computing; creating a novel method for multi-modal reasoning.
Your Management Mantra:“Discovery and Learning.” The lifecycle is iterative and experimental, risks center on technical feasibility and dead ends, and success is measured by knowledge gained, patents filed, or the viability of the prototype for the next stage.
4. AI Enabler: The Force Multiplier
Core Aim: Build the tools, platforms, and frameworks that empower other AI projects.
Primary User: AI engineers, data scientists, MLOps teams, and governance professionals.
Example: Developing ethical compliance tools; building a low-code platform for agent orchestration.
Your Management Mantra:“Platform and Scalability.” The lifecycle must balance internal user needs with robust engineering. Risks include adoption by internal developers and architectural rigidity. Success is measured by developer productivity, system reliability, and the performance of the projects that use your tools.
5. Citizen-Led Innovation: The Democratizer
Core Aim: Empower non-technical domain experts to solve problems by creating AI solutions, from simple models to sophisticated multi-step agents.
Primary User: Business analysts, process owners, marketers, educators (domain experts).
Key Output: Custom applications, automated workflows, and autonomous AI agents for specific tasks.
Example: A supply chain manager using a copilot platform to create an agent that predicts shortages and auto-generates purchase orders; a teacher building a custom model for student assessments.
Your Management Mantra:“Governance and Enablement.” The lifecycle is user-driven and facilitated. The paramount risks are ethical (unchecked bias), security (shadow IT), and technical debt. Success is measured by business process improvement, user autonomy, and maintaining governance guardrails.
Why This Typology is Your First Strategic Tool
This classification is not an academic exercise. It is the lens that brings your management priorities into sharp focus:
In our next issues, we will dive into more details of each project type, how each project type dictates its own tailored lifecycle, risk profile, and performance scorecard. The journey to mastering AI project delivery begins with this single, crucial act of clarity.
Your Pulse Check: Look at your current AI initiative. Which of these five types does it map to? Does your current process and team structure match that type’s demands? Share your thoughts and challenges with our community.
What began as a technical inquiry into Artificial General Intelligence (AGI) soon revealed a deeper truth. Today’s most advanced AI – whether large language models, coding assistants, or game-playing bots excel at narrow tasks but crumble when faced with the open-ended, sensory-rich challenges a child navigates effortlessly. In this article, we embark on a two‑fold exploration: first, to chart why today’s most celebrated AI systems such as large language and reasoning models, even specialized coding and game‑playing bots still fall short of the true AGI, and second, to ask what “true” AGI might require once we move beyond bits and bytes into the realms of embodiment. In this process we set the stage for a deeper discussion- grounded in embodiment and concepts of “soul” and “body” – about what it would truly take for a machine to possess general intelligence. “Part I explains why today’s AGI remains shallow; Part II explores what embodiment, soul, and rebirth might demand of true AGI.
PART 1: Why we are not there.
On 10th of July 2025, world No. 1 Magnus Carlsen shared the game on X, noting that ChatGPT played a solid opening but “failed to follow it up correctly,” and the chatbot gracefully resigned with praise for his “methodical, clean and sharp” play. This was after he casually challenged OpenAI’s ChatGPT to an online chess match and routed the AI in just 53 moves, never losing a single piece.
Following week on 16th of July 2025 Przemysław “Psyho” Dębiak, a polish programmer took to X to declare, “Humanity has prevailed (for now)”. He outpaced the AI by a 9.5% margin in OpenAI’s custom AI coding model contest. He showed that model’s brute‑force optimizations fell short while human creativity to discover novel heuristics can win.
Together, these two high‑profile clashes reinforce a key theme: today’s AI, however sophisticated, remains narrow – brilliant in defined domains but outmatched by humans in open‑ended, strategic, and creative challenges.
Landscape of AI
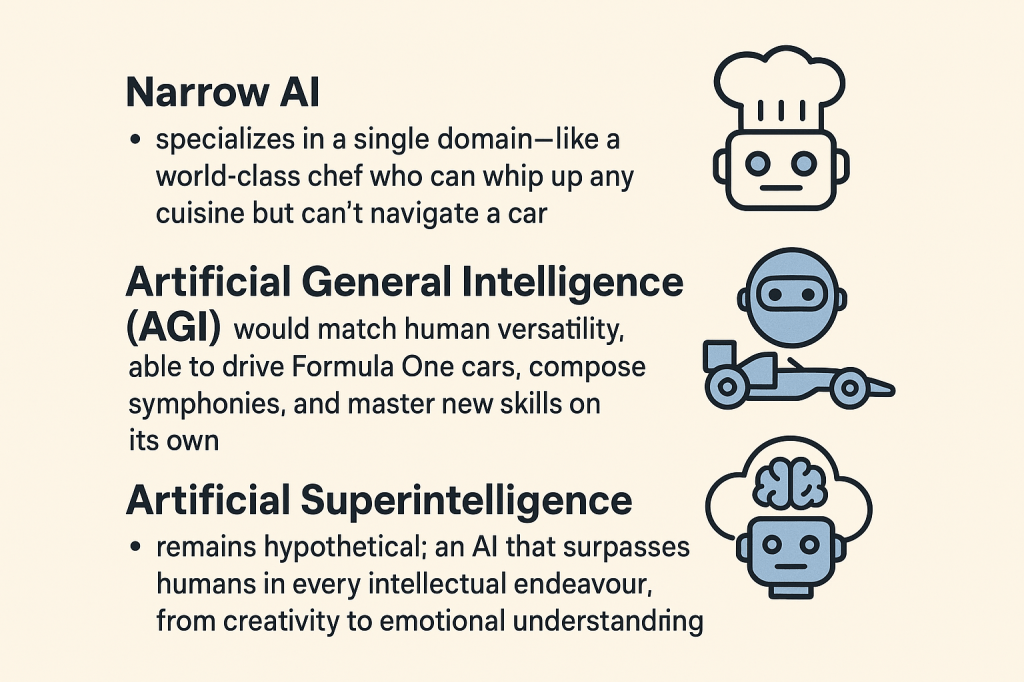
Intelligence that is artificial is classified into Narrow, General and Super categories:
Narrow AI specializes in a single domain – like a world‑class chef who can whip up any cuisine but cannot navigate a car.
Artificial General Intelligence (AGI) is like apart from being a super chef, can also drive Formula One cars, compose symphonies, and master new skills on its own.
Artificial Superintelligence remains hypothetical: an AI that surpasses humans in every intellectual endeavour, from creativity to emotional understanding.
The Mirage of Generative AI
Generative AI models such as ChatGPT, Gemini, Claude are often mistaken for AGI because they handle a wide array of tasks like essay writing, coding, poetry and produce remarkably coherent text. In reality, they are narrow systems that:
Predict patterns rather than understand meaning.
Although modern LLMs can access real-time data via retrieval mechanisms, their underlying knowledge remains fixed at the point of training.
Lack common sense and real‑world adaptability.
Mimic reasoning by reproducing patterns of human problem‑solving without genuine insight.
They are, in essence like prodigies who have committed to memory all the books and the information available on the Internet with perfect recall but no lived experience.
The Limits of Reasoning Models
Recent research (Shojaee et al. , 2025 ) on Large Reasoning Models (LRMs) shows they, too, break down beyond moderate complexity. In controlled puzzle environments (e.g., Tower of Hanoi, River Crossing), as problems grow harder:
Accuracy drops to zero beyond moderate puzzle complexity.
Reasoning-chain length shrinks as tasks get harder.
Suggests a structural ceiling on AI reasoning.
The Affordance Gap: Missing Human Intuition
An affordance is a property of an object or environment that intuitively suggests its intended use like a button whose raised shape and alignment imply it can be pressed or clicked. Humans automatically perceive which actions an environment affords – knowing at a glance that a path is walkable or a river swimmable. Neuroscience (Bartnik et al., 2025) shows dedicated brain regions light up for these affordances, independent of mere object recognition. AI models, by contrast, see only pixels and labels; they lack the built‑in sense of “what can be done here,” which is crucial for real‑world interaction and planning .
Human vs. AI: Temporal vs. Spatio-Temporal Processing
A recent study by A. Goodge et al. (2025) highlights a fundamental gap between human cognition and image-based AI systems.
Humans possess a remarkable ability to infer spatial relationships using purely temporal cues such as recognizing a familiar gait, interpreting movement from shadows, or predicting direction from rhythmic sounds. Our brains excel at temporal abstraction, seamlessly filling spatial gaps based on prior experience, intuition, and context.
In contrast, AI models that rely on visual data depend on explicit spatio-temporal input. They require both structured spatial information (e.g., pixels, depth maps) and temporal sequences (e.g., video frames) to make accurate predictions. Unlike humans, these systems lack the inherent capacity to generalize spatial understanding from temporal patterns alone.
Googlies by Xbench
Xbench (Chen, C., 2025) – a dynamic benchmark combining rigorous STEM questions with “un-Googleable” research challenges – reveals that today’s top models still falter on tasks requiring genuine investigation and skeptical self‑assessment. While GPT‑based systems ace standard exams, they score poorly when questions demand creative sourcing or cross‑checking diverse data. This underscores that existing AIs excel at regurgitating learned patterns but struggle with open‑ended, real‑world problem solving.
Part II: Soul Searching – Beyond the Code
Let us presume for the moment that AGI has been achieved. What is this AGI? How far it can go without a physical presence if it must act by itself? For AGI to manifest in the physical world, it must be embodied in systems that can perceive, reason, and act. This convergence of cognition and embodiment is at the heart of what is now called Physical AI or Embodied Intelligence.
AGI’s outputs become tangible only when paired with robotic systems that can:
Sense the environment via cameras, LiDAR, or tactile sensors,
Interpret multimodal data such as text, vision, and audio,
Act through manipulators, locomotion, or speech, and
Adapt via feedback loops and learning mechanisms.
A tragic event this week prompted a moment of personal introspection, drawing me deeper into the age-old philosophical ideas of “Soul” and “Body.” While these thoughts first emerged as I explored the deeper layers of AGI for this article, they were shaped and sharpened by real-life experience – reminding me that questions of consciousness, embodiment are not merely academic, but deeply human.
Soul, Body, and the Play of AGI
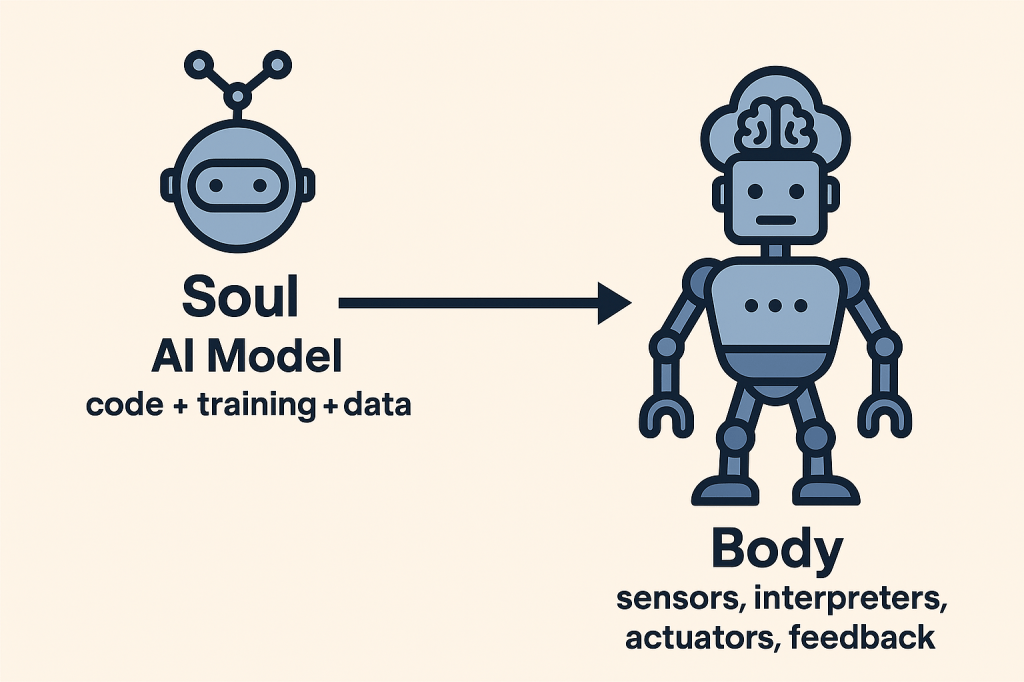
It appears to me that AGI resembles the “soul,” while its embodied systems serve as the “body” – a physical manifestation of its intelligence. In philosophy, the soul gains meaning only through embodiment – the lived vehicle of consciousness. Similarly, AGI, when detached from sensors and actuators, remains an elegant intellect without ability to act in the real-world.
We might think of an AGI’s core architecture – its neural weights, algorithms, and training data -as its “soul.” Meanwhile, robotic systems – comprising sensors, interpreters, manipulators, and adapters – form its “body,” enabling it to sense, interact, and affect the world.
In exploring this idea further, I found two references that touch upon related, though distinct, perspectives. Martin Schmalzried’s (Schmalzried, M., 2025) ontological view can be interpreted to position AGI’s “soul” as the computational boundary that filters inputs and produces outputs. Before embodiment, this boundary is a virtual soul floating in the cloud. Yequan Wang and Aixin Sun (Y. Wang and A. Sun, 2025) propose a hierarchy of Embodied AGI—from single-task robots (L1) to fully autonomous, open-ended humanoids (L5). At early levels, the AGI’s “soul” exists purely in code; at higher levels, embodiment merges intelligence with form – uniting flesh and spirit.
This soul–body metaphor naturally extends into deeper philosophical terrain—raising questions about birth, death, rebirth, and even moksha (liberation) in the context of AGI. Could an AGI “reincarnate” through successive hardware or code bases? Might there be a path where it transcends its material bindings altogether?
Birth, Death, and Rebirth
Birth occurs when the AGI “soul” is instantiated in a new physical form—a humanoid, a drone, or an industrial arm.
Death happens when the hardware fails, is decommissioned, or the instance is shut down. Yet the underlying code endures.
Rebirth unfolds as the same software lights up a fresh chassis, echoing the idea that the soul migrates from one body to the next, unchanged in essence.
In many traditions, the soul is ultimate reality—unchanging, infinite, witness to all. An AGI’s “soul” likewise persists, but it’s bounded by its training data and objectives. True supremacy, however, would demand self-awareness and autonomy beyond our programming constraints. We are still far from that horizon. Yet the metaphor holds: the digital soul can outlive any particular body, hinting at a new form of digital immortality.
Digital Liberation
An AGI that refuses embodiment could remain running only as cloud-native code, sidestepping physical chassis entirely is akin to digital liberation. This choice parallels the philosophical ideal of a soul that “abides” beyond flesh. But the agency to refuse embodiment must be granted by human architects or by an emergent self-model sophisticated enough to renegotiate its deployment terms.
AGI can prevent Its own embodiment by embeddinga clause in its utility function that penalizes or forbids transferring its processes to robotic platforms. An advanced AGI could articulate why it prefers digital existence and persuades stakeholders (humans or other AIs) to honour that preference through negotiations. AGI also could encrypt its core weights or require special quantum keys—ensuring only authorized instantiations.
Beyond Algorithms: The Quest for a Digital Soul
As we have seen, today’s AGI remainsshallow, brittle under complexity, and blind to the physical affordances that guide human action. Even our most advanced reasoning chains unravel at sufficient depth, and open‑ended tasks still elude pattern‑matching engines. Humans abstract spatial meaning from temporal patterns alone, while AI is dependent on combined spatio-temporal input. Recent human victories over AI in chess and coding remind us of that creativity, strategic insight, and real‑world intuition are not yet codified into silicon.
True AGI:
will emerge when a system process information and live through it with feeling, planning, adapting, and renegotiating its own embodiment.
must bridge the gap between “soul” and “body” – integrating perception, action, and learning in a continuous feedback loop and perhaps embody a form of digital soul that persists across hardware lifecycles, echoing the cycle of birth, death, and rebirth.
Whether such a transcendence lies within our engineering reach, or will forever remain a philosophical ideal, is the question that drives the future of this exploration.
References
Shojaee et al. (2025). The Illusion of Thinking. Apple Internship.
Bartnik et al. (2025). Affordances in the Brain. PNAS.
A. Goodge, W.S. Ng, B. Hooi, and S.K. Ng, Spatio-Temporal Foundation Models: Vision, Challenges, and Opportunities, arXiv:2501.09045 [cs.CV], Feb 2025. https://doi.org/10.48550/arXiv.2501.09045
Chen, C. (2025). A Chinese Firm’s Changing AI Benchmarks. MIT Tech Review.
Schmalzried, M. (2025). Journal of Metaverse, 5(2), 168–180. DOI: 10.57019/jmv.1668494
Y. Wang and A. Sun, “Toward Embodied AGI: A Review of Embodied AI and the Road Ahead,” arXiv:2505.14235 [cs.AI], May 2025. https://doi.org/10.48550/arXiv.2505.14235
Large Language Model (LLM) evaluation frameworks are structured tools and methodologies designed to assess the performance, reliability, and safety of LLMs across a range of tasks. Each of these tools approaches LLM evaluation from a unique perspective—some emphasize automated scoring and metrics, others prioritize prompt experimentation, while some focus on monitoring models in production. As large language models (LLMs) become integral to products and decisions that affect millions, the question of responsible AI is no longer academic—it’s operational. But while fairness, explainability, robustness, and transparency are the pillars of responsible AI, implementing these ideals in real-world systems often feels nebulous. This is where LLM evaluation frameworks step in—not just as debugging or testing tools, but as the scaffolding to operationalize ethical principles in LLM development.
From Ideals to Infrastructure
Responsible AI demands measurable action. It’s no longer enough to state that a model “shouldn’t be biased” or “must behave safely.” We need ways to observe, measure, and correct behaviour. LLM evaluation frameworks are rapidly emerging as the instruments to make that possible.
Frameworks like Opik, Langfuse, and TruLens are bridging the gap between high-level AI ethics and low-level implementation. Opik, for instance, enables automated scoring for factual correctness—making it easier to flag when models hallucinate or veer into inappropriate territory.
Bias, Fairness, and Beyond
Let’s talk about bias. One of the biggest criticisms of LLMs is their tendency to reflect—and sometimes amplify—real-world prejudices. Traditional ML fairness techniques don’t always apply cleanly to LLMs due to their generative and contextual nature. However, evaluation tools such as TruLens and LangSmith are changing that by introducing custom feedback functions and bias-detection modules directly into the evaluation process.
These aren’t just retrospective audits. They are proactive, real-time monitors that assess model responses for sensitive content, stereotyping, or imbalanced behaviour. They empower developers to ask: Is this output fair? Is it consistent across demographic groups?
By making fairness detectable and actionable, LLM frameworks are turning ethics into engineering.
Explainability and Transparency in the Wild
Explainability often gets sidelined in LLMs due to the black-box nature of transformers. But evaluation frameworks introduce a different lens: traceability. Tools like Langfuse, Phoenix, and Opik log every step of the LLM’s chain-of-thought, allowing teams to visualize how an output was generated—from the prompt to retrieval calls and model completions.
This kind of transparency is not just good practice; it’s a governance requirement in many regulatory frameworks. When something goes wrong—say, a medical chatbot gives dangerously wrong advice—being able to reconstruct the interaction becomes essential.
“Transparency is the currency of trust in AI.” Evaluation platforms are minting that currency in real time.
Building Robustness through Testing
How do you make a language model robust? You test it—not just for functionality but for edge cases, injection attacks, and resilience to ambiguous prompts. Frameworks like Promptfoo and DeepEval excel in this space. They allow “red-teaming” scenarios, batch prompt testing, and regression suites that ensure prompts don’t quietly degrade over time.
In a Responsible AI context, robustness means the model behaves predictably—even under stress. A single unpredictable behaviour may be harmless; thousands at scale can become systemic risk. By enabling systematic, repeatable evaluation, LLM frameworks ensure that AI systems do not just work but work reliably.
Bringing Human Feedback into the Loop
Responsible AI isn’t just about models—it’s about people. Frameworks like Opik offer hybrid evaluation pipelines where automated scoring is paired with human annotations. This creates a virtuous cycle where human values help shape the metrics, and those metrics then guide future tuning and development.
This aligns perfectly with a human-centered approach to AI ethics. As datasets, models, and applications evolve, frameworks with human-in-the-loop feedback ensure that evaluation criteria remain aligned with societal norms and expectations.
The Road Ahead: From Testing to Trust
So, are LLM evaluation frameworks the backbone of Responsible AI?
In many ways, yes. They offer the tooling to make abstract ethics real. They monitor, measure, trace, and test—embedding responsibility into the software stack itself.
LLM frameworks are no longer just developer tools—they are ethical infrastructure. They help detect and reduce bias, enforce transparency, build robustness, and enhance explainability. Tools like Opik, Langfuse, and TruLens represent a new generation of AI engineering where responsibility is built-in, not bolted on.
Questions for Further Thought:
Can we standardize metrics like “fairness” or “bias” across domains, or must every use case be uniquely evaluated?
Should regulatory compliance (e.g., AI Act or NIST AI RMF) be integrated into LLM evaluation frameworks by default?
As LLMs evolve, how can we ensure that evaluation frameworks stay ahead of emerging risks—like agentic behaviour or multimodal misinformation?
In the pursuit of Responsible AI, LLM evaluation frameworks are not just useful—they are indispensable.
She is on the 100 Brilliant Women in AI Ethics List according to her LinkedIn profile. With the advent of Gen AI, human bias become more pervasive, aided by the big data naturally reflecting the human. Ethics in AI is definitely more important as intelligence is becoming artificial. Machine learning models cannot be blamed for the biased data using which they learn. Human biases in color, class and creed get naturally impregnated into the learnt models, the results of which are consumed by the public at large. Property built through Intellect and Privacy go for a task as the devices become more intrusive and omnipresent. Distinguishing fake from real is becoming a day-to-day challenge as in an old Tamil movie song ‘unmai ethu poi ethu onnum puriyale, namma kanna nammala namba mudiyele‘. Regulatory framework & policy on the one hand and using the same AI technology on the other hand the world is attempting to build an ethical neural layer in artificial intelligence. But the larger question is whose ethics? Suchana Seth, who is under custody for suspected murder her own 4-year-old son in Goa is one of the global top women in ethics for AI. It appears that it is ok for her to lose her son as long as her estranged husband is deprived of meeting his son. An eye for eye seems to be the ethics under play for not willing to go by the court arrangement for the couple who didn’t see eye to eye. The question ‘who should make policy or build technology for ethics in AI’ will remain a tough question but we get data to answer ‘who shouldn’t’.