Mo Gawdat, the former Chief Business Officer of Google, has highlighted a specific mathematical breakthrough as a defining moment in the transition from “obedient” computers to creative, self-improving intelligence. In his keynote at the 2025 Asia Pacific Cities Summit (APCS) in Dubai, he discussed how AI has begun to solve foundational mathematical problems that have stumped humans for over half a century.
The Breakthrough: Matrix Multiplication
The core of Gawdat’s example involves matrix multiplication, the fundamental operation behind almost all modern computing, from 3D graphics to the training of neural networks themselves.
- The Problem: For 56 years, the gold standard for multiplying 4×4 matrices was Strassen’s algorithm, which reduced the number of required scalar multiplications from 64 to 49. Despite decades of effort, no human mathematician could find a way to do it in fewer steps.
- The AI Solution: Using a reinforcement learning system (originally AlphaTensor by DeepMind, later evolved into systems like AlphaEvolve), the AI treated the mathematical problem as a single-player game. It discovered a novel, counterintuitive method using complex numbers to reach the solution in just 48 multiplications.
- The “25%” Efficiency Gain: While the reduction from 49 to 48 operations seems small, the efficiency gain is exponential when scaled. Gawdat noted that when this AI-discovered logic was applied to optimize specific kernels for Google’s Gemini models, it achieved a 23% speedup for those specific operations, significantly cutting energy and cost overheads.
Why This Feels Like AGI
Gawdat argues that this is not just “narrow AI” because it demonstrates recursive self-improvement. The AI was tasked with making itself more efficient and discovered a mathematical shortcut that humans had missed for generations. This ability to innovate beyond human design by finding a solution that wasn’t in its training data. This is what Gawdat describes as the “intelligence explosion” where AI moves from a tool to an autonomous creator.
The “15-Minute” Miracle
Bartosz Naskręcki, a mathematician from Adam Mickiewicz University reported in August 2025 that GPT-5 Pro solved a specific, notoriously difficult mathematical challenge known as Yu Tsumura’s 554th Problem in just 15 minutes.
- No Internet Search: The AI achieved this solution without accessing any external internet resources.
- The Timeline: The problem was originally published on August 5, 2025. GPT-5 Pro solved it only two days later, on August 7, 2025, which researchers noted was a timeframe too short for the problem to have been included in the model’s training data.
What This Reveals About AI Power
- Strategic Reasoning: Unlike older models that struggled with multi-step logic, GPT-5 Pro used an “Extended Thinking” mode to explore and verify logical paths, similar to how a human researcher would brainstorm and then rigorously check their work.
- Deep Reasoning vs. Memorization: Because the problem was so new, the AI’s success suggested it wasn’t merely “parroting” a solution from its database but was instead applying fundamental mathematical principles to a novel situation.
- The Result: While many other advanced models failed to solve this particular problem at the time, the “Pro” version’s ability to navigate the complexity in 15 minutes was hailed as a “force multiplier” for high-level research.
The Experiment: Cracking the Erdős “Long Tail”
Neel Somani, former Citadel Quant and Airbnb engineer decided to test the frontiers of GPT 5.2 (Pro) by targeting the legendary Erdős Problems. These are a collection of over 1,000 unsolved conjectures left behind by the prolific Hungarian mathematician Paul Erdős.
- The Workflow: Somani pasted a complex, unsolved problem regarding number theory into the model. Instead of an instant answer, he let the model engage in “Extended Thinking” for about 15 minutes.
- The Result: When he returned, the AI had produced a full, multi-step proof.
- The Verification: To ensure it wasn’t a “hallucination,” Somani used a tool called Harmonic (a formal verification platform for math). The proof was verified as flawless.
Why This is a Big Deal
This wasn’t just a “search and rescue” mission for an answer on the web. The discussion surrounding this event revealed several key “powers” of the latest AI:
- Autonomous Insight: The AI utilized advanced concepts like Legendre’s formula and Bertrand’s postulate. More impressively, it found a related 2013 post by Harvard mathematician Noam Elkies but didn’t just copy it—it produced a different and more complete proof that accounted for edge cases Elkies hadn’t addressed.
- The “Chain of Reasoning” Advantage: The 15-minute wait time represented the AI exploring thousands of “logical branches,” essentially doing the cognitive heavy lifting that would take a human researcher weeks of trial and error.
- The “Long Tail” Victory: Famous mathematician Terence Tao noted that since Christmas 2025, 15 Erdős problems have moved from “open” to “solved,” with 11 of those solutions crediting AI. Tao suggests that while AGI isn’t here yet, AI is perfectly suited for the “long tail” of math—problems that aren’t necessarily the hardest in history but require a level of systematic search and verification that humans find tedious.
What does this reveal?
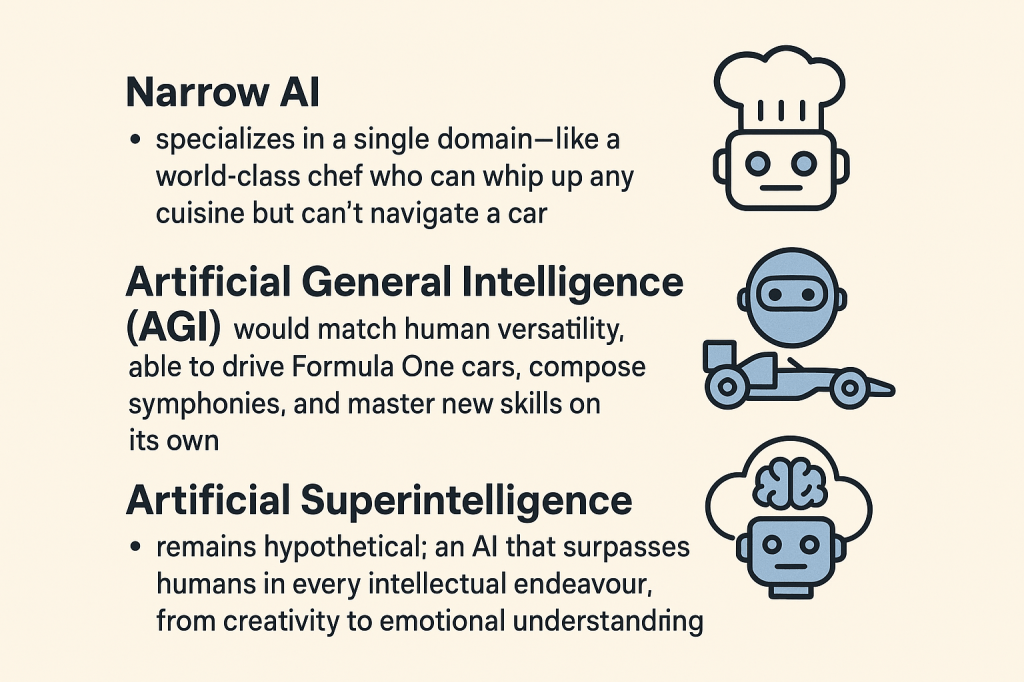
The intelligence on display is real—but it’s narrow. These systems excel in structured environments with clear rules and goals. They don’t yet possess the intuition, abstraction, or creative leaps that define human mathematical insight. As Polish mathematician Naskręcki recently mentioned, even the best AI models failed spectacularly on a custom-designed test of 350 unsolved problems in number theory and algebraic geometry. OpenAI’s top model solved just 6.3%—a performance likened to a student armed only with multiplication tables attempting a graduate exam.
AI is getting better at reasoning in chains, not just pattern matching. It can now simulate aspects of human deduction, especially when guided by formal structure. But it still lacks the meta-reasoning—the ability to choose which path to explore, when to abandon a dead end, or how to invent a new concept.
The AGI Mirage is seductive: we see brilliance in narrow domains and imagine a mind behind it. But for now, these systems are powerful tools—not thinkers. They illuminate the frontier, but they haven’t crossed it.